If you are trying to develop a python package and facing difficulties in doing so, this article may help.
The Issue
Recently, I was trying to develop a python package for a data science project. I generated my project using Data Science Cookiecutter. The folders were organized in the following way –
├── LICENSE
├── Makefile <- Makefile with commands like `make data` or `make train`
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── docs <- A default Sphinx project; see sphinx-doc.org for details
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
│
├── setup.py <- makes project pip installable (pip install -e .) so src can be imported
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ │
│ ├── data <- Scripts to download or generate data
│ │ └── make_dataset.py
│ │
│ ├── features <- Scripts to turn raw data into features for modeling
│ │ └── build_features.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make
│ │ │ predictions
│ │ ├── predict_model.py
│ │ └── train_model.py
│ │
│ └── visualization <- Scripts to create exploratory and results oriented visualizations
│ └── visualize.py
│
└── tox.ini <- tox file with settings for running tox; see tox.testrun.org
In Python, you can install your local package using pip install -e .
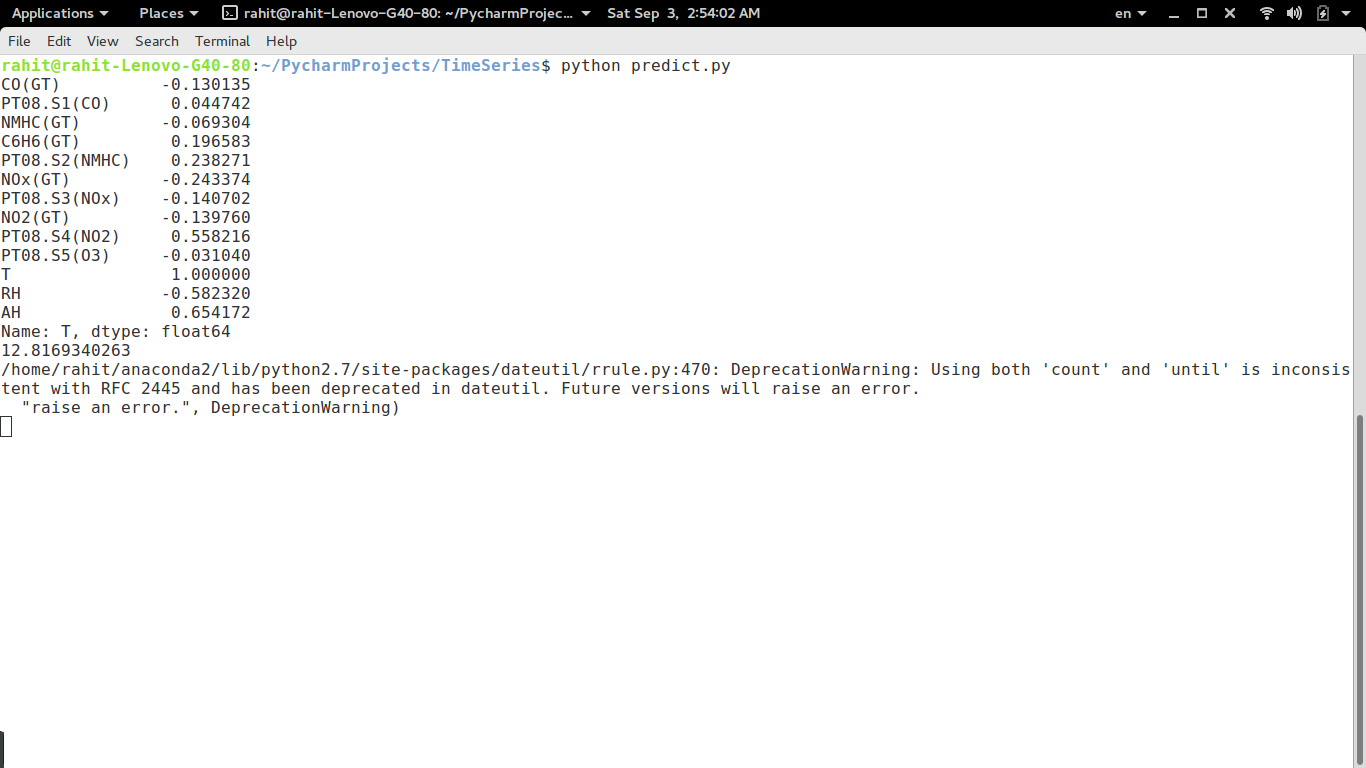
Despite developing my own package before, I was not able to properly install and import it this time.
>>> import my_pacakge
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named my_package
What I tried-
__init__.py
checking pip listmy_package
checking sys.pathpip install -e .sys.path
I was using conda on windows. So I thought it was some permission issue. So I followed this and gave all the permissions for Anaconda. But that does not solve the problem either. I still thought it was some windows/conda permission or path related issue until I installed another local development package of mine. That package works!!
So it has to be some setup.py
In the working version – all of my source code for the package was in a root folder with the same name of the package. But in the current one, root folder for all the package code is src folder and I tried to declare setup.py
from setuptools import find_packages, setup
setup(
name='my_package',
package_dir={'': 'src'},
packages=find_packages('src'),
version='0.1.0',
)
I tried to print find_packages(‘src’) and it was returning the modules perfectly – ['my_package', 'my_package.data', 'my_package.features', 'my_package.models', 'my_package.visualization']
The Solution (or Problem?)
With hours of searching, I found the real problem in this very old github issue posted in pip repo (also here). It seems setuptools (and thus pip) does not like renaming the package root folder in developer mode. Finally, the problem was resolved by creating a folder with the same name as the package (inside srcsrcsrc/tests
The original issue, however, remain unresolved. I have not found anything that follows up the issue on Pip or setuptools repository.
# setup.py
from setuptools import find_packages, setup
setup(
name='my_package',
package_dir={'': 'src'},
packages=find_packages('src'),
version='0.1.0',
description='A short description of the project.',
author='K.M. Tahsin Hassan Rahit'
)
├── LICENSE
├── Makefile
├── README.md
├── data
├── docs
├── models
├── notebooks
├── references
├── reports
├── requirements.txt
├── setup.py <- makes project pip installable (pip install -e .) so src can be imported
├── src
│ ├── my_package <- Source code for use in this project.
│ │ ├── __init__.py <- Makes my_package a Python module
│ │ ├── data
│ │ │ └── __init__.py <- Makes my_package.data a Python module
│ │ │ └── make_dataset.py
│ │ │
│ │ ├── features
│ │ │ └── __init__.py <- Makes my_package.features a Python module
│ │ │ └── build_features.py
│ │ │
│ │ ├── models
│ │ │ └── __init__.py <- Makes my_package.models a Python module
│ │ │ ├── predict_model.py
│ │ │ └── train_model.py
│ │ │
│ │ └── visualization
│ │ │ └── __init__.py <- Makes my_package.visualization a Python module
│ │ │ └── visualize.py
│ ├── tests <- Tests file for my source code
│
└── tox.ini